一起来写个简单的解释器(11)
英文出处:Ruslan’s Blog
- 《一起来写个简单的解释器(1)》
- 《一起来写个简单的解释器(2)》
- 《一起来写个简单的解释器(3)》
- 《一起来写个简单的解释器(4)》
- 《一起来写个简单的解释器(5)》
- 《一起来写个简单的解释器(6)》
- 《一起来写个简单的解释器(7)》
- 《一起来写个简单的解释器(8)》
- 《一起来写个简单的解释器(9)》
- 《一起来写个简单的解释器(10)》
我前几天坐在房间里,思考我们已经覆盖了多少解释器相关的知识点,我想我会扼要概述下到目前为止所学到的知识,以及我们将要学习的内容。

到目前为止,我们已经学习了:
- 如何将句子分解成标记,这个过程被称为词法分析(lexical analysis),解释器的这部分被称为词法分析器(lexical analyzer), 词法分析器lexer, 扫描器(scanner) 或 标记器(tokenizer) 。我们已经学会了如何从头开始编写我们自己的词法分析器,而不使用正则表达式或Lex等工具。
- 如何识别标记流中的短语。在标记流中识别短语的过程,或者换言之,在标记流中找到结构的过程称为 解析(parsing) 或 语法分析(syntax analysis) 。解释器或编译器中执行这部分任务的部分被称为 解析器(parser) 或 语法分析器(syntax analyzer)。
- 如何用 语法图(syntax diagrams) 表示编程语言的语法规则,语法图是编程语言语法规则的图形表示。语法图可视化地显示我们的编程语言允许有哪些语句,不允许有哪些语句。
- 如何使用另一个广泛使用的符号来指定编程语言的语法。它被称为 上下文无关语法(context-free grammars ),简称 语法(grammars) 或 BNF (巴克斯 - 诺尔形式)。
- 如何将语法映射到代码以及如何编写 递归下降解析器(recursive-descent parser) 。
- 如何写一个真正的基本的解释器。
- 运算符的 结合性(associativity) 和 优先级(precedence) 如何工作,以及如何使用优先级表构造语法。
- 如何构建一个解析句子的 抽象语法树 (Abstract Syntax Tree,AST),以及如何将Pascal中的整个源程序表示为一个大的AST。
- 如何遍历一个AST,以及如何作为一个AST节点的访问者实现我们的解释器。
凭借我们所掌握的所有知识和经验,我们建立了一个解释器,可以扫描、解析和构建AST,并通过遍历AST,解释我们第一个完整的Pascal程序。女士们,先生们,我诚恳地想,如果你已经达到这个目标,你应该得到鼓掌,但不要高兴过头。继续前进,即使我们已经涵盖了很多地方,未来道路上还有更令人兴奋的部分。
通过到目前为止所做的一切,我们已经准备好处理如下主题:
- 嵌套的程序和函数
- 过程和函数调用
- 语义分析(类型检查,确保变量在使用之前被声明,并简单检查程序是否有意义)
- 控制流程元素(如IF语句)
- 聚合数据类型(记录)
- 更多的内置类型
- 源码级调试器
- 杂项,所有其他上面没有提到的 :)
但在我们讨论这些话题之前,我们需要建立一个坚实的基础。
这是我们开始深入探索符号,符号表和范围这个超级重要话题的地方。这个话题本身将包括几篇文章。你将看到为什么这很重要。好吧,我们开始打好这个基础吧!
首先,让我们来谈谈符号以及为什么我们需要跟踪它们。什么是 符号(symbol) ?出于我们的目的,我们非正式地将符号定义为一些程序实体的标识符,如变量,子例程或内置类型。为使符号有用,它们至少需要具有关于它们识别的程序实体的以下信息:
- 名称(例如’x’,’y’,’number’)
- 类别(它是一个变量,子程序或内置类型?)
- 类型(INTEGER,REAL)
今天我们将解决变量符号和内置类型符号,因为我们以前已经使用过变量和类型。顺便说一下,“内置”类型意味着一种没有被你自己定义的类型,并且可以立即使用,比如之前见过和使用过的INTEGER和REAL类型。
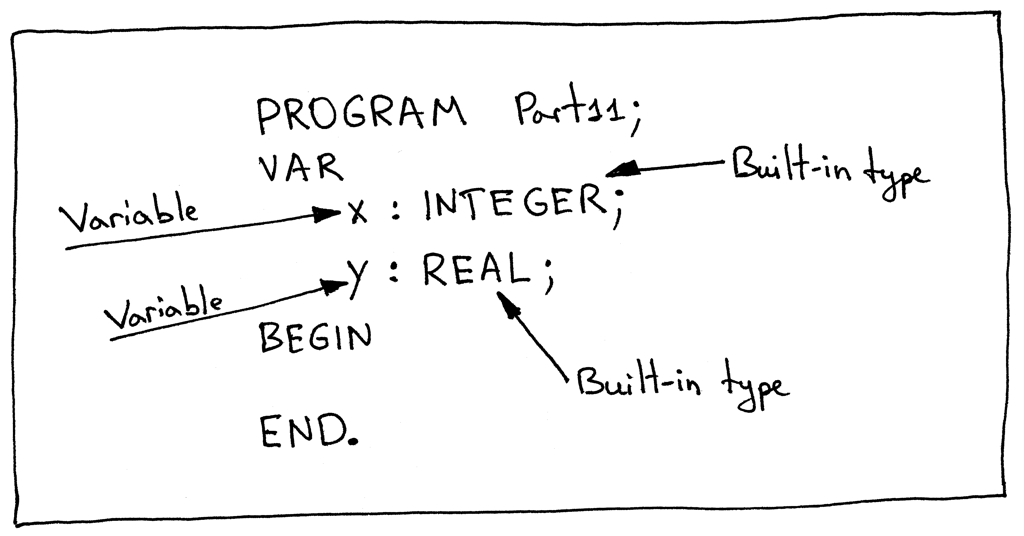
让我们来看看下面的Pascal程序,特别是在变量声明部分。您可以在下面的图片中看到该部分有四个符号:两个变量符号(x和y)和两个内置类型符号(INTEGER和REAL)。
我们如何在代码中表示符号?让我们在Python中创建一个基类Symbol类:
class Symbol(object):
def __init__(self, name, type=None):
self.name = name
self.type = type
正如你所看到的,这个类接受了 name 参数和一个可选的 type 参数(并不是所有的符号都可能有一个与之相关的类型)。那符号的类别呢?我们将在类名称本身中对符号的类别进行编码,这意味着将创建单独的类来表示不同的符号类别。
我们从基本的内置类型开始。目前为止,我们已经看到了两个内置类型,声明变量时的:INTEGER和REAL。我们如何在代码中表示一个内置的类型符号?这里有一个选项:
class BuiltinTypeSymbol(Symbol):
def __init__(self, name):
super(BuiltinTypeSymbol, self).__init__(name)
def __str__(self):
return self.name
__repr__ = __str__
该类继承自 Symbol 类,构造函数只需要该类型的名称。类别在类名中编码,而内置类型符号的基类的 type 参数是 None 。双下划线或dunder(为“Double UNDERscore”)方法 str和repr是特殊的Python方法,定义它们使得当您打印符号对象时,具有友好的格式化消息。
下载解释器文件并将其保存为spi.py;从保存spi.py文件的相同目录启动python shell,并使用我们刚才定义的类来交互:
$ python
>>> from spi import BuiltinTypeSymbol
>>> int_type = BuiltinTypeSymbol('INTEGER')
>>> int_type
INTEGER
>>> real_type = BuiltinTypeSymbol('REAL')
>>> real_type
REAL
我们怎样才能表示一个可变的符号?我们来创建一个 VarSymbol 类:
class VarSymbol(Symbol):
def __init__(self, name, type):
super(VarSymbol, self).__init__(name, type)
def __str__(self):
return '<{name}:{type}>'.format(name=self.name, type=self.type)
__repr__ = __str__
在类中,我们使 name 和 type 为必须参数,类名 VarSymbol 清楚地表明类的一个实例将标识一个变量符号(该类别是可变的)。
回到交互式python shell,看看如何为我们的变量符号手动构建实例,我们已经知道如何构建 BuiltinTypeSymbol 类实例:
$ python
>>> from spi import BuiltinTypeSymbol, VarSymbol
>>> int_type = BuiltinTypeSymbol('INTEGER')
>>> real_type = BuiltinTypeSymbol('REAL')
>>>
>>> var_x_symbol = VarSymbol('x', int_type)
>>> var_x_symbol
<x:INTEGER>
>>> var_y_symbol = VarSymbol('y', real_type)
>>> var_y_symbol
<y:REAL>
如您所见,我们首先创建一个内置类型符号的实例,然后将其作为参数传递给 VarSymbol 的构造函数。
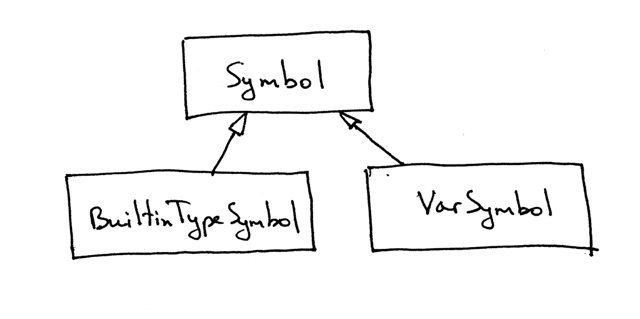
以下是定义的符号的层次结构:
一切都还不错,但我们还没有回答这个问题,为什么我们需要首先跟踪这些符号。
这里是一些原因:
- 为了确保当我们为变量赋值时,类型是正确的(类型检查)
- 确保变量在使用前被声明
看看下面不正确的Pascal程序,例如:
![]()
上面的程序有两个问题(你可以自己用fpc编译它看看):
- 在表达式 “x := 2 + y;” 中,我们为被声明为整数的变量 “x” 赋予了一个小数值。 这不会编译,因为类型是不兼容的。
- 在赋值语句 “x := a;” 中,我们引用了未声明的变量“a” —— 错误!
为了能够运行时在解释/运算程序的源代码之前识别这种情况,我们需要跟踪程序符号。 在哪里存储跟踪的符号? 我想你已经猜到了——在符号表中!
什么是 符号表 ? 符号表是用于跟踪源代码中的各种符号的抽象数据类型( ADT )。 今天我们将符号表作为一个单独的类来实现并实现一些有用的方法:
class SymbolTable(object):
def __init__(self):
self._symbols = OrderedDict()
def __str__(self):
s = 'Symbols: {symbols}'.format(
symbols=[value for value in self._symbols.values()]
)
return s
__repr__ = __str__
def define(self, symbol):
print('Define: %s' % symbol)
self._symbols[symbol.name] = symbol
def lookup(self, name):
print('Lookup: %s' % name)
symbol = self._symbols.get(name)
# 'symbol' is either an instance of the Symbol class or 'None'
return symbol
我们将用符号表执行两个主要操作:存储符号并按名称查找。因此,我们需要两个辅助方法 - define 和 lookup。
方法define将符号作为参数,并将其作为参数存储内部_symbols有序字典中,使用符号的名称作为键,符号实例作为值。 方法lookup将一个符号名称作为参数,如果找到它,则返回一个符号,否则返回“None”。
让我们为最近使用的,手动创建变量和内置类型符号的Pascal程序,手动填充符号表:
PROGRAM Part11;
VAR
x : INTEGER;
y : REAL;
BEGIN
END.
重新启动一个Python shell并执行一下内容:
$ python
>>> from spi import SymbolTable, BuiltinTypeSymbol, VarSymbol
>>> symtab = SymbolTable()
>>> int_type = BuiltinTypeSymbol('INTEGER')
>>> symtab.define(int_type)
Define: INTEGER
>>> symtab
Symbols: [INTEGER]
>>>
>>> var_x_symbol = VarSymbol('x', int_type)
>>> symtab.define(var_x_symbol)
Define: <x:INTEGER>
>>> symtab
Symbols: [INTEGER, <x:INTEGER>]
>>>
>>> real_type = BuiltinTypeSymbol('REAL')
>>> symtab.define(real_type)
Define: REAL
>>> symtab
Symbols: [INTEGER, <x:INTEGER>, REAL]
>>>
>>> var_y_symbol = VarSymbol('y', real_type)
>>> symtab.define(var_y_symbol)
Define: <y:REAL>
>>> symtab
Symbols: [INTEGER, <x:INTEGER>, REAL, <y:REAL>]
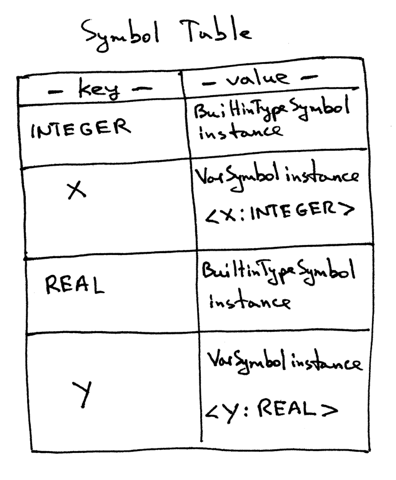
如果你看了 _symbols 字典的内容,它将和下面的内容相似:
我们如何自动化构建符号表的过程? 我们将仅仅编写另一个节点访问者,访问我们的解析器构建的AST! 这是另一个有像AST这样的中间表示是多么有用的例子。 我们不用扩展解析器来处理符号表,而是分离关注点并编写一个新的节点访问者类。 简洁漂亮。:)
在这之前,让我们扩展我们的 SymbolTable 类,以在符号表实例化时初始化内置类型。 以下是SymbolTable类的完整源代码:
class SymbolTable(object):
def __init__(self):
self._symbols = OrderedDict()
self._init_builtins()
def _init_builtins(self):
self.define(BuiltinTypeSymbol('INTEGER'))
self.define(BuiltinTypeSymbol('REAL'))
def __str__(self):
s = 'Symbols: {symbols}'.format(
symbols=[value for value in self._symbols.values()]
)
return s
__repr__ = __str__
def define(self, symbol):
print('Define: %s' % symbol)
self._symbols[symbol.name] = symbol
def lookup(self, name):
print('Lookup: %s' % name)
symbol = self._symbols.get(name)
# 'symbol' is either an instance of the Symbol class or 'None'
return symbol
现在看看AST节点访问者 SymbolTableBuilder :
class SymbolTableBuilder(NodeVisitor):
def __init__(self):
self.symtab = SymbolTable()
def visit_Block(self, node):
for declaration in node.declarations:
self.visit(declaration)
self.visit(node.compound_statement)
def visit_Program(self, node):
self.visit(node.block)
def visit_BinOp(self, node):
self.visit(node.left)
self.visit(node.right)
def visit_Num(self, node):
pass
def visit_UnaryOp(self, node):
self.visit(node.expr)
def visit_Compound(self, node):
for child in node.children:
self.visit(child)
def visit_NoOp(self, node):
pass
def visit_VarDecl(self, node):
type_name = node.type_node.value
type_symbol = self.symtab.lookup(type_name)
var_name = node.var_node.value
var_symbol = VarSymbol(var_name, type_symbol)
self.symtab.define(var_symbol)
你已经在Interpreter类中看到过大多数方法,但 visit_VarDecl 方法值得特别关注。再看一遍:
def visit_VarDecl(self, node):
type_name = node.type_node.value
type_symbol = self.symtab.lookup(type_name)
var_name = node.var_node.value
var_symbol = VarSymbol(var_name, type_symbol)
self.symtab.define(var_symbol)
此方法负责访问VarDecl AST节点,并将相应的符号存储在符号表中。 首先,该方法在符号表中按名称查找内置的类型符号,然后创建VarSymbol类的一个实例并将其存储(定义)到符号表中。
在实际情况下来试试我们的SymbolTableBuilder AST访问方法:
$ python
>>> from spi import Lexer, Parser, SymbolTableBuilder
>>> text = """
... PROGRAM Part11;
... VAR
... x : INTEGER;
... y : REAL;
...
... BEGIN
...
... END.
... """
>>> lexer = Lexer(text)
>>> parser = Parser(lexer)
>>> tree = parser.parse()
>>> symtab_builder = SymbolTableBuilder()
Define: INTEGER
Define: REAL
>>> symtab_builder.visit(tree)
Lookup: INTEGER
Define: <x:INTEGER>
Lookup: REAL
Define: <y:REAL>
>>> # Let’s examine the contents of our symbol table
…
>>> symtab_builder.symtab
Symbols: [INTEGER, REAL, <x:INTEGER>, <y:REAL>]
在上面的交互式会话中,您可以看到“Define:…”和“Lookup:…”消息的序列,这些消息显示了在符号表中定义和查找符号的顺序。 会话中的最后一个命令将打印符号表的内容,您可以看到它与之前手动构建的符号表的内容完全相同。 AST节点访客的神奇之处在于他们几乎为你做了所有的工作。:)
我们已经可以很好地使用我们的符号表和符号表生成器:我们可以使用它们来验证变量是否在赋值和表达式中使用之前被声明。 我们所需要做的就是用另外两种方法扩展访问者: visit_Assign 和 visit_Var :
def visit_Assign(self, node):
var_name = node.left.value
var_symbol = self.symtab.lookup(var_name)
if var_symbol is None:
raise NameError(repr(var_name))
self.visit(node.right)
def visit_Var(self, node):
var_name = node.value
var_symbol = self.symtab.lookup(var_name)
if var_symbol is None:
raise NameError(repr(var_name))
如果在符号表中找不到符号,这些方法将引发NameError异常。
看看下面的程序,我们引用尚未声明的变量“b”:
PROGRAM NameError1;
VAR
a : INTEGER;
BEGIN
a := 2 + b;
END.
让我们看看会发生什么,如果我们为程序构建一个AST并将其传递给符号表生成器来访问:
$ python
>>> from spi import Lexer, Parser, SymbolTableBuilder
>>> text = """
... PROGRAM NameError1;
... VAR
... a : INTEGER;
...
... BEGIN
... a := 2 + b;
... END.
... """
>>> lexer = Lexer(text)
>>> parser = Parser(lexer)
>>> tree = parser.parse()
>>> symtab_builder = SymbolTableBuilder()
Define: INTEGER
Define: REAL
>>> symtab_builder.visit(tree)
Lookup: INTEGER
Define: <a:INTEGER>
Lookup: a
Lookup: b
Traceback (most recent call last):
...
File "spi.py", line 674, in visit_Var
raise NameError(repr(var_name))
NameError: 'b'
正是我们期待的!
这里还有一个错误的例子,我们试图给一个尚未定义的变量赋值,在这个例子中是变量“a”:
PROGRAM NameError2;
VAR
b : INTEGER;
BEGIN
b := 1;
a := b + 2;
END.
同时,在Python shell中:
>>> from spi import Lexer, Parser, SymbolTableBuilder
>>> text = """
... PROGRAM NameError2;
... VAR
... b : INTEGER;
...
... BEGIN
... b := 1;
... a := b + 2;
... END.
... """
>>> lexer = Lexer(text)
>>> parser = Parser(lexer)
>>> tree = parser.parse()
>>> symtab_builder = SymbolTableBuilder()
Define: INTEGER
Define: REAL
>>> symtab_builder.visit(tree)
Lookup: INTEGER
Define: <b:INTEGER>
Lookup: b
Lookup: a
Traceback (most recent call last):
...
File "spi.py", line 665, in visit_Assign
raise NameError(repr(var_name))
NameError: 'a'
太好了,我们的新访问者方法捕捉到了这个问题!
我想强调的一点是,我们的SymbolTableBuilder AST访问者所做的所有检查都是在运行时之前完成的,所以在我们的解释器实际执行源程序之前。如果要解释下面的程序,要把这个观点带回家:
PROGRAM Part11;
VAR
x : INTEGER;
BEGIN
x := 2;
END.
程序退出前,符号表和运行时GLOBAL_MEMORY的内容如下所示:
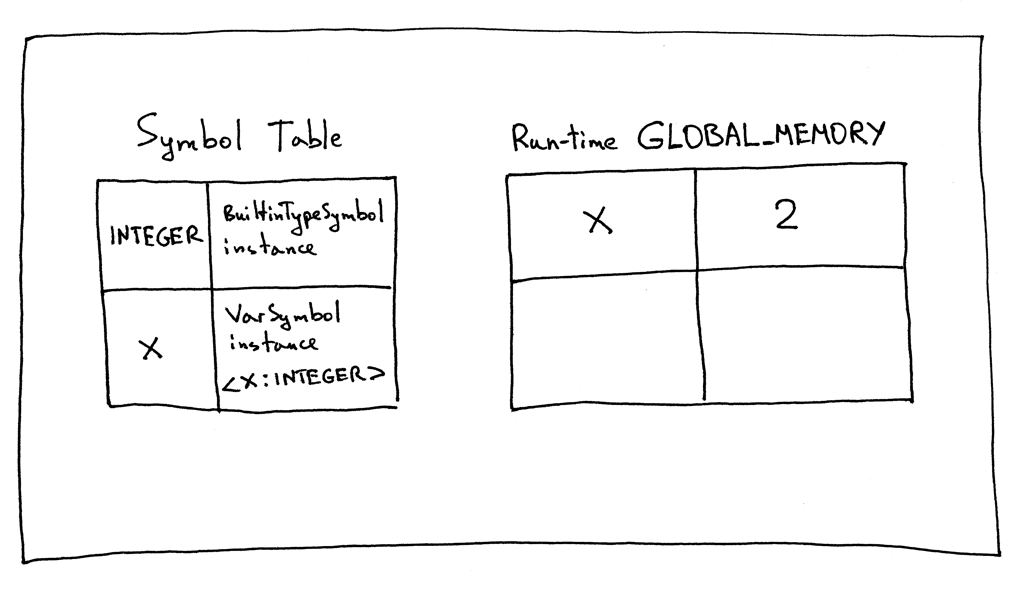
你看到差别了吗? 你能看到符号表不保存变量“x”的值2吗? 这完全是解释者的工作。
记住第9篇中将符号表用作全局内存的图片了吗?
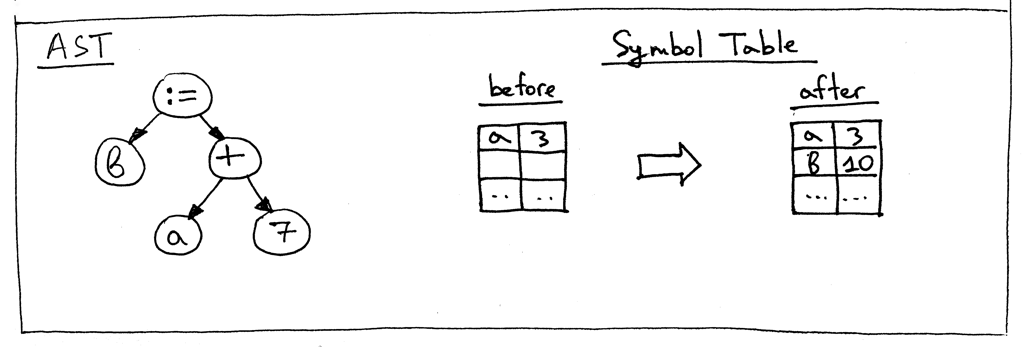
没了! 我们有效地摆脱了符号表作为全局内存的双重责任。
让我们把它放在一起,用下面的程序来测试我们的新解释器:
PROGRAM Part11;
VAR
number : INTEGER;
a, b : INTEGER;
y : REAL;
BEGIN {Part11}
number := 2;
a := number ;
b := 10 * a + 10 * number DIV 4;
y := 20 / 7 + 3.14
END. {Part11}
以part11.pas保存程序并启动解释器:
$ python spi.py part11.pas
Define: INTEGER
Define: REAL
Lookup: INTEGER
Define: <number:INTEGER>
Lookup: INTEGER
Define: <a:INTEGER>
Lookup: INTEGER
Define: <b:INTEGER>
Lookup: REAL
Define: <y:REAL>
Lookup: number
Lookup: a
Lookup: number
Lookup: b
Lookup: a
Lookup: number
Lookup: y
Symbol Table contents:
Symbols: [INTEGER, REAL, <number:INTEGER>, <a:INTEGER>, <b:INTEGER>, <y:REAL>]
Run-time GLOBAL_MEMORY contents:
a = 2
b = 25
number = 2
y = 5.99714285714
请你注意到 Interpreter 类与构建符号表无关的事实,它依赖于 SymbolTableBuilder 以确保源码中的变量在被解释器使用前被正确的声明。
检查你的理解
- 什么是符号?
- 为什么我们需要跟踪符号?
- 什么是符号表?
- 定义符号和解析/查找符号有什么区别?
给定下面这个小的Pascal程序,符号表的内容是什么,全局内存呢?(GLOBAL_MEMORY字典是解释器的一部分)
PROGRAM Part11; VAR x, y : INTEGER; BEGIN x := 2; y := 3 + x; END.
这就是今天。在下一篇文章中,我将讨论作用域,我们将动手解决解析嵌套过程的问题。敬请期待,再见!请记住,无论如何,“继续前进!”
P.S:我对符号和符号表管理主题的解释深受Terence Parr的《Language Implementation Patterns》一书影响。这是一本了不起的书。我认为它是我所见过的对符号表最清晰的解释,它也涵盖了类范围,这是我不打算在本系列中讨论的一个话题,因为我们不会讨论面向对象的Pascal。
P.P.S .:如果你等不及想开始深入了解编译器,我强烈推荐Jack Crenshaw的免费经典 “Let’s Build a Compiler.”。
顺便说一下,我正在编写一本叫《Let’s Build A Web Server: First Steps》的书,解释如何从头开始编写基本的Web服务器。你可以在这里,这里和这里查看这本书。